Alertes basées sur le risque, comment faire passer votre SOC à la prochaine étape.

Important: Cet article ne gratte que la surface de ce que sont les alertes basées sur le risque (Risk-based Alerting). L’objectif n’est que de vous faire part de cette méthode de génération d’alerte afin d’ajouter une corde à votre arc et d’ajouter un peu de contexte à mon support visuel fourni lors du dernier Hackfest où j’ai présenté la session sur ce sujet. Je crois sincèrement qu’on peut combattre la fatigue des alertes et augmenter le « bonheur » des analystes en impliquant le RBA dans le quotidien d’un SOC. Bonne lecture!
« Est-ce qu’on pourrait attribuer un score de risque sur des événements ou détections et générer un cyberincident seulement si on dépasse un certain niveau? ».
Voici un très court extrait d’une discussion bien plus longue dans un bar à Montréal avec mes collègues il y a déjà presque 2 ans. Je me rends au bureau quelques fois par mois durant l’été et c’est toujours de bons moments pour se réunir pour un 5@tard. Ça donne toujours place à de belles discussions et on a tellement eu souvent des discussions sur les scores de risque qu’on avait plus le choix, on devait prendre action.
Pourquoi ça revenait constamment? On était déterminé à trouver une solution pour régler certains enjeux potentiels comme la fatigue des alertes et on devait maintenir un excellent niveau de mobilisation en s’assurant que les analystes fassent ce qu’ils aimaient faire: analyser et répondre à des cyberincidents, non pas traiter mécaniquement des alertes et des faux positifs sans arrêt.
J’ai récemment présenté une session sur le sujet au Hackfest à Lévis, je suis plutôt dans le style présentation PowerPoint sans trop de détail et plus de « blabla » au grand détriment de ceux qui aiment obtenir les copies des présentations pour revoir le contenu. Cet article viendra donc complémenter le support visuel que j’avais créé précédemment. Évidemment, je n’ai pas pour intention d’écrire tout ce que j’ai discuté dans cette session, donc advenant que vous désiriez en apprendre un peu plus ou si vous avez des questions, contactez-moi directement!
Copie PDF de ma présentation disponible en cliquant ici.
On se lance…
Les multitudes de solutions de sécurité génèrent des centaines de détections et même en essayant de filtrer au maximum ces alertes, c’est un combat pratiquement sans fin. C’est difficile d’avoir une vue d’ensemble sur un cyberincident plus complexe qui comporte plusieurs étapes à l’attaque quand on traite de façon individuelle les alertes. Un gros avantage de fonctionner avec des alertes basées sur le risque est que nous pouvons « lire une histoire », elle sera composée de plusieurs événements ayant chacun un score associé.
Allons-y avec un exemple concret:
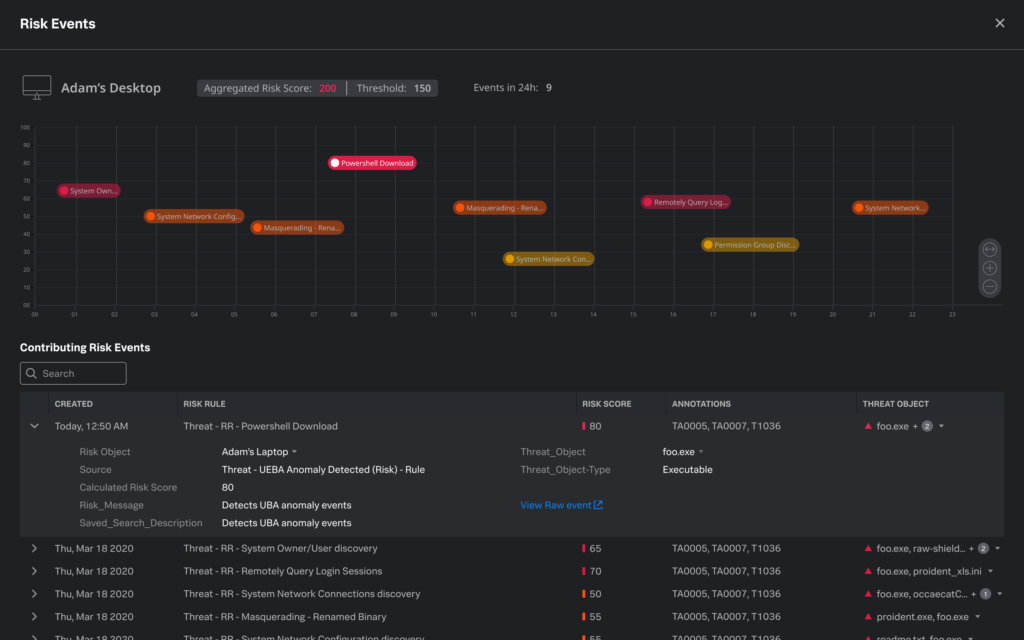
Beaucoup plus parlant n’est-ce pas? Normalement, il est possible que chacun des événements ait été traité de façon indépendante, mais en recevant une alerte qui contient l’ensemble de ces événements, l’analyste possède maintenant une vue rapide de l’attaque en cours et honnêtement, un bon analyste va être en mesure de déterminer presque immédiatement s’il s’agit d’une activité suspecte ou non.
Déterminer le score d’un événement
Bien qu’il n’existe pas de recette magique pour déterminer le score d’un événement, il est très important de rester constant dans la façon qu’on le définit. Plusieurs facteurs peuvent influencer celui-ci et je dirais que la position dans la séquence de l’attaque est l’élément le plus important. Pour nous aider avec ceci, on peut utiliser le MITRE ATT&CK Framework, chaque tactique en partant de l’accès initial jusqu’à l’impact pourrait avoir un multiplicateur de plus en plus grand puisque plus on se dirige vers l’impact, plus l’attaque risque d’être importante.
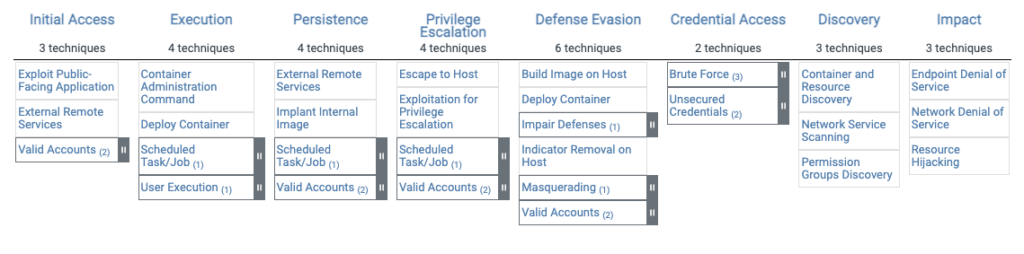
D’autres éléments peuvent entrer en jeu, est-ce qu’un objet de risque (Adresse IP, nom de domaine, signature numérique, etc.) est déjà connu par diverses sources d’intelligence et représente une menace confirmée? Est-ce que le compte utilisateur impliqué est un compte à hauts privilèges? Est-ce que le poste de travail est impliqué dans d’autres cyberincidents au cours des dernières semaines? Voici plusieurs facteurs qui feraient en sorte que nous pourrions ajouter de la valeur au score de risque initial.
En terminant
On ne peut pas passer du jour au lendemain à la méthode d’alertes basées sur le risque et cela va demander un travail continuel afin de maintenir la pertinence de celle-ci. Il faut passer en revue chacune des alertes de vos solutions actuelles et déterminer son score. Il est également possible que pour certaines alertes, vous désiriez absolument qu’elle génère un cyberincident pour qu’il soit traité immédiatement (Ça serait irréaliste de se dire qu’on doit absolument tout passer en alerte basée sur le risque, une partie de vos alertes seront difficilement transposables).
Il faut corréler des événements ensemble dans une période de temps prédéterminée, cela va clairement ajouter un certain risque puisqu’il est possible qu’avant que vous receviez une alerte basée sur le risque il puisse s’être passé quelques heures. Par contre, c’est exactement cette balance qu’il faut trouver et cela est spécifique aux besoins de votre organisation. Certaines préféreront obtenir des alertes plus rapidement vs. moins d’alertes, mais qui seraient clairement plus juste et signe de véritable situation à traiter.

J’ai la chance d’avoir plusieurs collègues et équipes compétentes qui travaillent sur ce sujet (Clin d’oeil à notre chef d’orchestre M. S. sans qui toutes ces discussions auraient peut-être été inutiles). C’est un travail complexe et où il est impossible de confirmer avec certitude si la limite que nous définissons est correcte ou encore si nous avons bien choisi les alertes à transformer en événement de risque.
Vous aurez besoin de plusieurs cerveaux pour réfléchir aux options et choix qui s’offriront à vous, le meilleur conseil que je pourrais vous donner est de bien tester vos requêtes avant de passer cette méthode en production et de vérifier quelles alertes vous auriez vu immédiatement et lesquelles plus tard et si cela est acceptable pour vous et votre organisation.
Références: